
Seit Tagen mache ich mir Gedanken über meinen Weg zur eigenen Website. Grundlegend muss ich wohl noch viel weiters Wissen über HTML und vor allem auch CSS sammeln, bevor ich weitere, tiefgründigere Entscheidungen treffen kann.
Artikel 2: Das Fundament
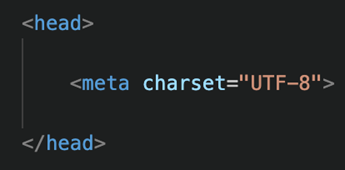
Das Fundament jeder Website besteht aus mehreren Teilen. Zwei sehr wichtige Pfeiler sind jedoch der Head und Body. Beide wurden in Kapitel 2 schon mal erwähnt. Also möchte ich hier noch etwas genauer auf beides eingehen.
Kapitel 4: Head & Body
Der Head
Der Head besteht aus mehreren Meta-Daten, welche so nicht direkt für den End-User auf der Website angezeigt werden. Diesen Teil der Website möchte und muss ich am Anfang meiner Reise noch sehr kurzhalten, da mein eigener Wissensstand noch begrenzt ist. Dennoch habe ich ein paar erste Informationen zu teilen. Angefangen mit dem Titel.
Der <title> wird bei HTML genutzt, um Text in der Titelleiste anzeigen zu lassen. Demonstrieren möchte ich es anhand von Google.

Der Titel kann und sollte noch ausführlicher genutzt werden. Hierzu aber an einer anderen Stelle mehr. Noch sind wir lange nicht bei Suchmaschinenoptimierung.
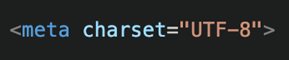
Ein weiterer Teil des Head-Bereichs ist das Charset. Dieser soll der Hauptinhalt des heutigen Blog-Beitrags sein.
Der Body
Der <body> stellt einen Platz dar, um tatsächlichen Inhalt anzugeben. Im Body findet man die Überschriften, welche man auf der Website sehen kann. Man findet den Text, der angezeigt wird, und man findet Bilder. In den Body kann man quasi jede Form von Medien und Kommunikation einsetzen, die man sich nur vorstellen kann.
Kapitel 5: Plain Text
Die Reise, auf welche wir uns heute begeben, beginnt am Anfang der Menschheitsgeschichte. Schon früh haben unsere Vorfahren mit Text kommuniziert. Damals noch per Symbolen in Höhlen. Aber Text bleibt Text. Höhlenmalereien waren natürlich nicht die einzigen textgebundenen Kommunikationsversuche der Menschheit auf dem Weg zur Computer-Ära.
Eine weitere lobenswerte Text-Codierungs-Idee kam von Samuel F. B. Morse. Er entwickelte 1837 eine zeitbasierte Codierung, welche lange Zeit von vielen Nationen dieser Welt als Standard genutzt wurde. Erst im Zeitalter von Computern musste der Vorläufer des modernen Binärcodes ersetzt werden.
Im Zeitraum zwischen 1950 und 1960 sind immer mehr Mitstreiter auf dem Computermarkt aufgetaucht. IBM und Univac, zwei Wettstreiter aus den frühen Jahren des PC-Baus, seien hier nur als Beispiel genannt. Viele unterschiedliche Firmen haben PCs gebaut und angeboten. Diese Maschinen hatten alle individuelle herstellerspezifische Codierung und es gab keinen Standard.
Somit hatte jeder Computer eine andere Art und Weise, mit Text umzugehen. Eine Textdatei, welche von Computer A erstellt wurde, konnte bei Computer B nicht angezeigt werden. Dies führte schnell zum Wunsch einer gemeinsamen Codierung, einer gemeinsamen „Sprache“.
Kapitel 6: ASCII
Computer benutzen Binärcode (Bits), um Informationen zu speichern oder zu senden. Der Binärcode besteht aus 0 und 1. An oder aus. So weit, so verständlich.
Im Zeitalter des Morse-Codes wurde ein Signal mit einer zeitlich begrenzten Codierung versehen und konnte so vom Empfänger ausgelesen werden. Unter dem „American Standard Code for Information Interchange“ (kurz ASCII) sollte nun eine gemeinsame Codierung für alle geschaffen werden. Hierzu wurde jedem Buchstaben eine Zahl zugeordnet. Diese Zahl wurde dann in Bits umgewandelt, um sie auf Computern speichern und auslesen zu können.
Beispiel Buchstabe A
Buchstabe A
→ ASCII: 65
→ Binär: 0 1 0 0 0 0 0 1
1 2 3 4 5 6 7 8
Ein Buchstabe unter ASCII besteht aus 7 Bits, also die binäre Nummer, unter der das Zeichen gespeichert wird, ist 7 Bits lang. Damit reden wir von 2 hoch 7 möglichen Kombinationen – 128, um genau zu sein.
Aufmerksamen Lesern sollte im obigen Beispiel nun aber ein Fehler aufgefallen sein. Es wird die ganze Zeit von 7 Bit geredet, gespeichert wurde der Buchstabe aber als 8 Nummern. Dies lässt sich darauf zurückführen, dass die kleinste mögliche Speichereinheit, die es bei Computern gab, da es damals nur Systeme mit maximal 8-Bit-Architektur gab. Heutige Rechner haben intern eine größere Verarbeitungsbreite.
1 Byte sind aber 8 Bit und keine 7. Es wurde bei den ersten Modellen des ASCII-Codes ein Bit freigelassen, da dieser nicht gebraucht wurde. Man hatte alle Buchstaben des Alphabets abgedeckt. Das aber auch nur aus der egoistischen Sicht der Amerikaner. Ein Deutscher, ein Grieche oder ein Russe sah das anders.
Bei 128 möglichen Speicheroptionen war sogar genug Platz für jede Menge Sonderzeichen. Es wurden zum Beispiel auch das @ und mathematische Befehle wie + und – in den Code mit aufgenommen.
Dies wurde aber schnell auch wieder zu wenig.
Mit dem Extended ASCII und der Nutzung des 8. Bits in verschiedenen Codepages wurden dann auch Umlaute wie ä, ö und ü mit in den Code aufgenommen. Dieser wurde auf dem vollen Byte, also den vollen 8 Bit, gespeichert. Somit hatte man 2 hoch 8 – 256 mögliche Speicheroptionen.
Kapitel 7: Unicode
Mit der Aufnahme der Umlaute ä, ö und ü konnten nun auch viele Deutsche endlich die in der deutschen Sprache bekannten Umlaute auf Computern in der westlichen Hemisphäre anzeigen und benutzen. Auch gab es in anderen Ländern eigene Codepages. Zum Beispiel das arabische Alphabet hatte seine eigene Codepage. Die Pages konnten aber wieder nicht miteinander kommunizieren, wenn Zeichen nicht in beiden benutzen Pages vorhanden waren.
Somit war schlussendlich klar: Es brauchte eine weitere Innovation.
Es gibt viele Sprachen mit noch mehr Umlauten. Es musste etwas her, was alles in einem vereint.
Der Unicode wurde in seiner ersten Version 1991 veröffentlicht. Hauptaugenmerk bei diesem Code war es, „alle auf der Erde verwendeten Schriftzeichen in einem Code darstellen zu können“, um eine Passage aus der Vorlesung von Herrn Prof. Dr. Martin Wessner an der Hochschule Darmstadt zu zitieren.
Dies setzte man um, indem jedes Zeichen einem Hexadezimalwert mit vorgestelltem U+ zugewiesen wurde.
Beispiel:
U+0041 (dezimal 65; = „A“)
U+00DF (dezimal 223; = „ß“)
Der Unicode war eine super Idee, hatte nur ein paar Haken.
Also musste man noch mal ran.
Kapitel 8: UTF-8
Mit dem Unicode Transformation Format 8 versuchten zwei Entwickler, Ken Thompson und Rob Pike, einen auf der einen Seite zu ASCII rückwärtskompatiblen Code zu schaffen, welcher aber auch in der Lage sein musste, alle neuen Zeichen des Unicodes darstellen zu können, während er massiv Speicherplatz einsparte.
Die Lösung: UTF-8 ist variabel.
Je nach Zeichen verwendet UTF-8 1 bis 4 Byte. So spart man bei den meisten westlichen Sprachen fast die Hälfte an Speicherplatz. Alle Zeichen des ASCII-Codes wurden mit demselben Bitmuster übernommen, neue Zeichen wurden einfach ergänzt.
UTF-8 bleibt bis heute der Standard im Internet.
Kapitel 9: Charset-Syntax
Kommen wir auf die Charset-Syntax zurück, die ich am Ende des 4. Kapitels angesprochen habe. Die Charset-Syntax kommt mit in den Head und kommuniziert mit dem Browser, welche Zeichencodierung er verwenden soll. So können alle Browser universal den Text, welchen ich im Body definiere, anzeigen. Hier kann ich nun jeden Umlaut meiner und auch fremder Sprachen angeben, und dieser wird von jedem Browser an jedem Endgerät richtig angezeigt.
Nach diesem Exkurs möchte ich den heutigen Artikel beenden. Auch heute möchte ich die letzten Worte einem großen Denker der Menschheitsgeschichte widmen.
„Alles, was aus Einem und Nichts zusammengesetzt ist, kann alle Dinge hervorbringen.“
– Gottfried Leibniz, der Erfinder des Binärsystems
Bis zum nächsten Mal.
Samstag, 08.11.25
Schreibe einen Kommentar